Ubuntu One, Headless
Update: James Henstridge wrote u1ftp FTP Server/REST API client. This way you can use any FTP client to access Ubuntu One files.
Update: Another way is simply to use curl – Upload to Ubuntu One using curl.
Notice: To run real Ubuntu One syncdaemon in headless mode, see Ubuntu One Headless wiki page.
Another idea I have been thinking about for quite a long time but it became extremely simple after Ubuntu One introduced REST API for file access. This API is used by a really wonderful Ubuntu One Files application for Android by Michał Karnicki and Web&Mobile team and John’s u1rest library.
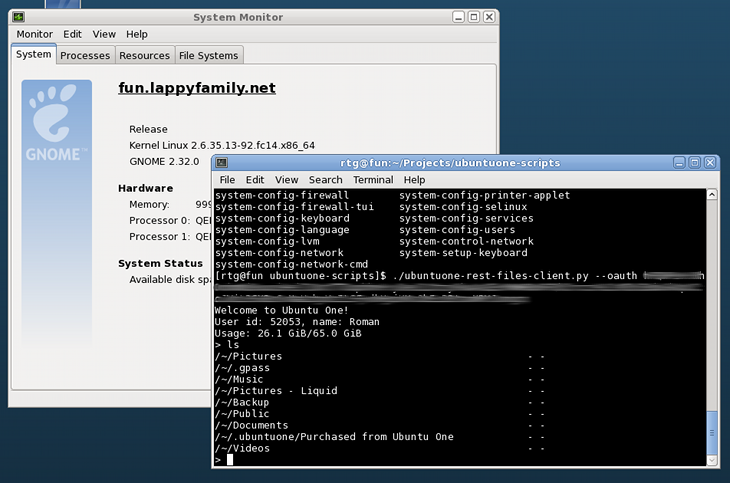
I decided to see how hard would it be to create a command line application similar to ftp to upload and download files and navigate my cloud storage using the API directly. The application needed to be usable in the server environment too.
This is the initial version:
rtg@lucidity:~$ ./ubuntuone-rest-files-client.py --oauth a:b:c:d Welcome to Ubuntu One! User id: 52053, name: Roman Usage: 26.1 GiB/65.0 GiB > ls /~/Pictures - - /~/.gpass - - /~/Music - - /~/Pictures - Liquid - - /~/Backup - - /~/Public - - /~/Documents - - /~/.ubuntuone/Purchased from Ubuntu One - - /~/Videos - - > cd ~/Documents /~/Documents> ls Articles/ 2011-04-05T20:07:40Z Certificates/ 2011-04-18T07:32:28Z CV/ 2010-12-01T11:14:08Z DVD Labels.odg 13332 2011-03-06T20:38:50Z eBooks/ 2011-08-05T15:08:03Z _image_vab-document.png 145336 2011-04-30T10:15:33Z ... /~/Documents> get _image_vab-document.png Downloading 145336 bytes to _image_vab-document.png... Done /~/Documents> cd ../Ubuntu\ One /~/Ubuntu One> put desktopcouch_0.6.4.orig.tar.gz Uploading desktopcouch_0.6.4.orig.tar.gz to https://files.one.ubuntu.com/content/~/Ubuntu%20One/desktopcouch_0.6.4.orig.tar.gz Content size: 105609 /~/Ubuntu One>
Well, you understand the idea. Please note that at the moment this is a very rough version, so download and use it if you really like to play with something that may suddenly break.
Where to get and how to use
You will need 2 files from ubuntuone-scripts repository – bzr branch
lp:~rye/+junk/ubuntuone-scripts, you can download the latest versions directly
from ubuntuone-sso-login.py and ubuntuone-rest-files-client.py. In order to get
the a:b:c:d values that are the value for --oauth option run the first script as
follows:
$ ./ubuntuone-sso-login.py Creating new entry for buzz SSO login: Your Ubuntu One SSO e-mail password: Your password Using SSO URL: https://login.ubuntu.com/api/1.0/authentications?ws.op=authenticate&token_name=%22Ubuntu+One+%40+buzz%22 OAuth info: a:b:c:d Ping result: ok 1/7
We are interested in the line after OAuth info. It will be a long string.
Warning! This OAuth string should be treated as secret, since it is composed of your OAuth consumer key:consumer secret:token:token secret. This string enables anybody who knows it to access your files, and CouchDB databases, think of it as a login/password pair that you can remove when needed. If you suspect that somebody else has that string, go to Ubuntu One web site and remove the corresponding entry. Then you can run ubuntuone-sso-login.py again and get a new set of credentials for the script.
Then run ubuntuone-rest-files-client.py:
./ubuntuone-rest-files-client.py --oauth a:b:c:d Welcome to Ubuntu One! User id: 52053, name: Roman Usage: 26.1 GiB/65.0 GiB >
That’s pretty much it. The following commands are supported:
get remote [local]– download the remote file as local, in case local name is omitted it will use the original nameput local [remote]– upload the local file, same rules for omitting the remote namemget remote1 [remote2 remote3 ... remoteN]– download the files to the current working directorycd folder– change remote directory. Please remember to quote the path if it contains spaces or escape them – "/~/Ubuntu One" or /~/Ubuntu Onequitor Ctrl+D – terminate the scriptls– list folder contents, in case some file is published the URL will be printedpublish remote– publish an already uploaded file. Will print public URLunpublish remote– take down the published file
More commands will be added later, at the moment this is a working proof of concept but I am very happy with the API so far. I will make the script much more stable and use less resources in the future (at the moment the whole file is read into memory during upload/download – thank you httplib2). Ah, by the way, it works on Fedora too: